Machine Learning : K Nearest Neighbors (KNN) Part 11
Let's assume we have 2 categories (Red & Green)
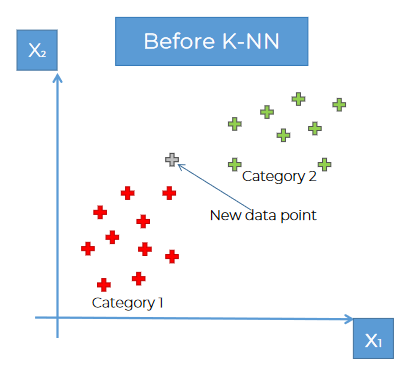
Now if we have a new data (white), where should we keep it?
Category 1 or, Category 2??
Using KNN , we basically assign that data to a category.
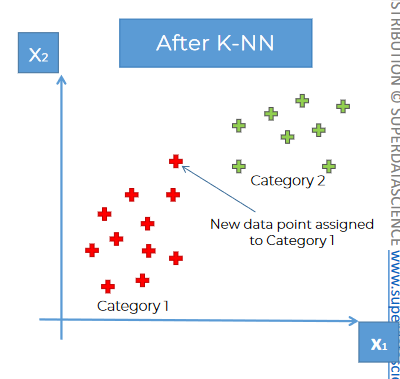
How to do that?
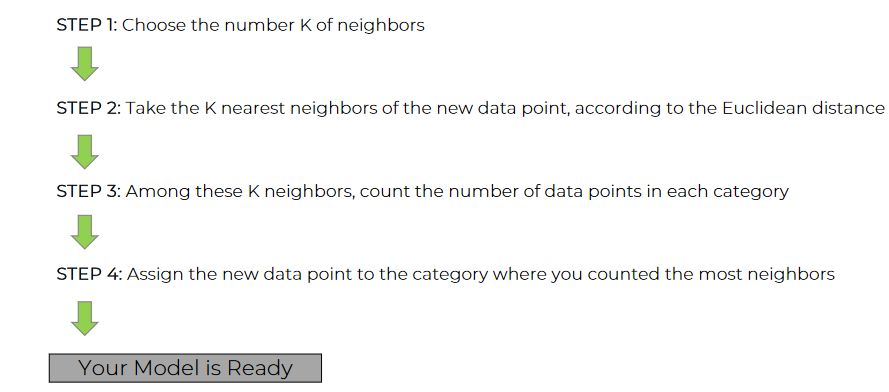
Let's practice now
Part 1: We have point between 2 categories.
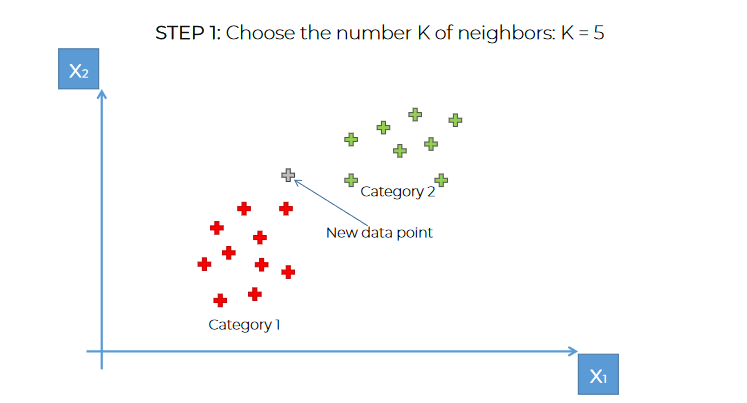
Part 2: Let's take 5 neighbors near that point
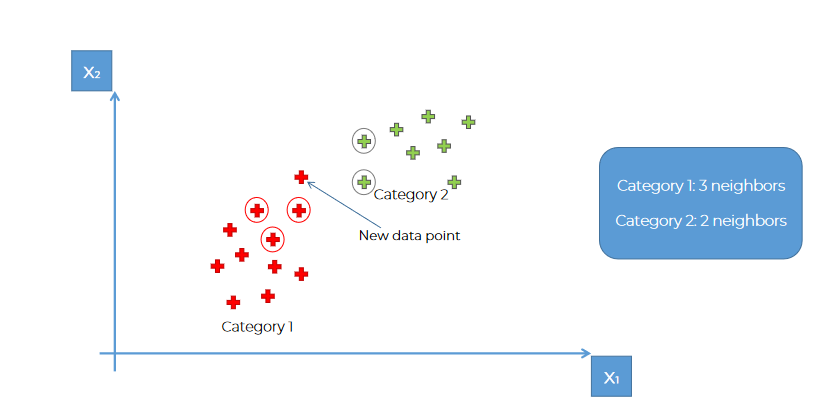
In Step 3 & Step 4:
As the number of neighbors in category 1 is 3 and number of neighbors in category 2 is 2, we will assign this point to Category 1
Let's code now
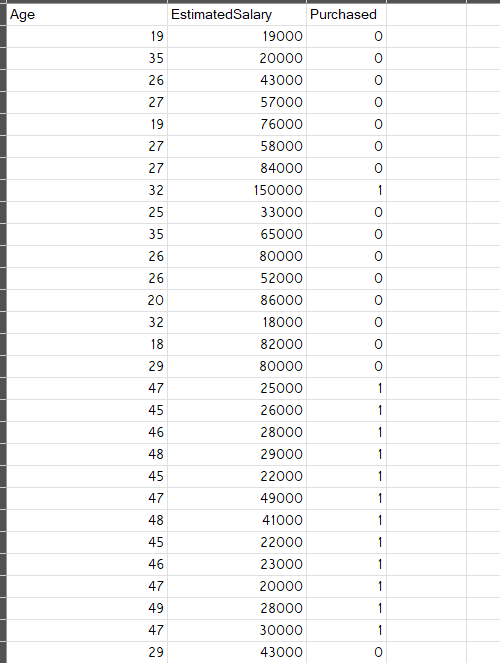
Problem statement: We are launching a new SUV in the market and we want to know which age people will buy it. Here is a list of people with their age and salary. Also, we have previous data of either they did buy any SUV before or not.
Let's import the library, upload dataset and split the dataset to 75% & 25%
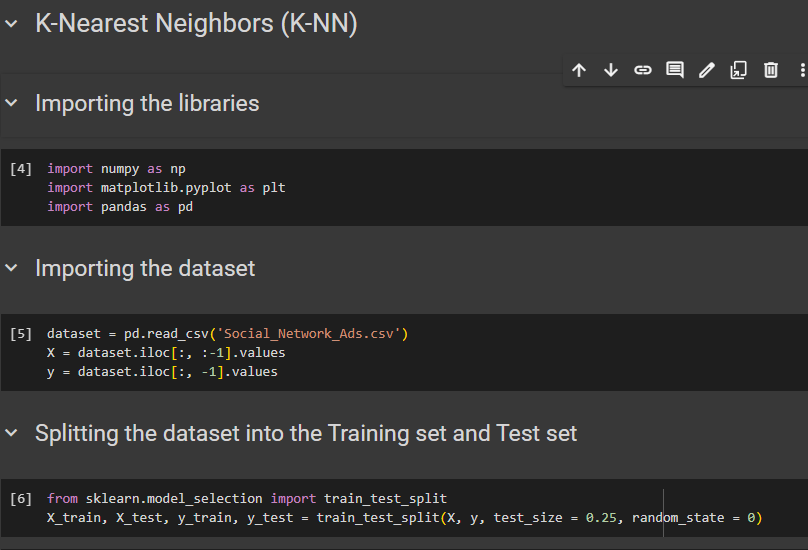
then feature scale
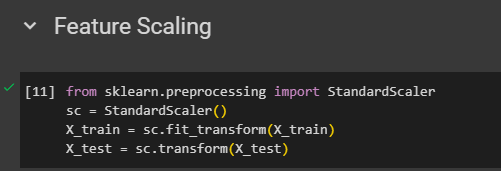
Training the KNN model
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)

We just used the default values for n_neighbors, metric and p. classifier.fit(X_train, y_train)
Predicting a new result
predicting a result for a 30year old person who earns 87000
print(classifier.predict(sc.transform([[30,87000]])))
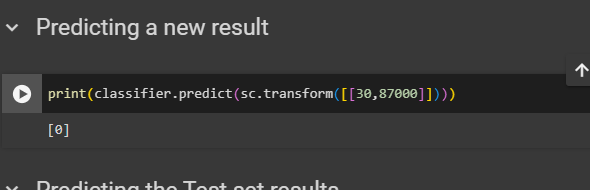
That means, this person won't buy the SUV
Predicting the Test set results
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
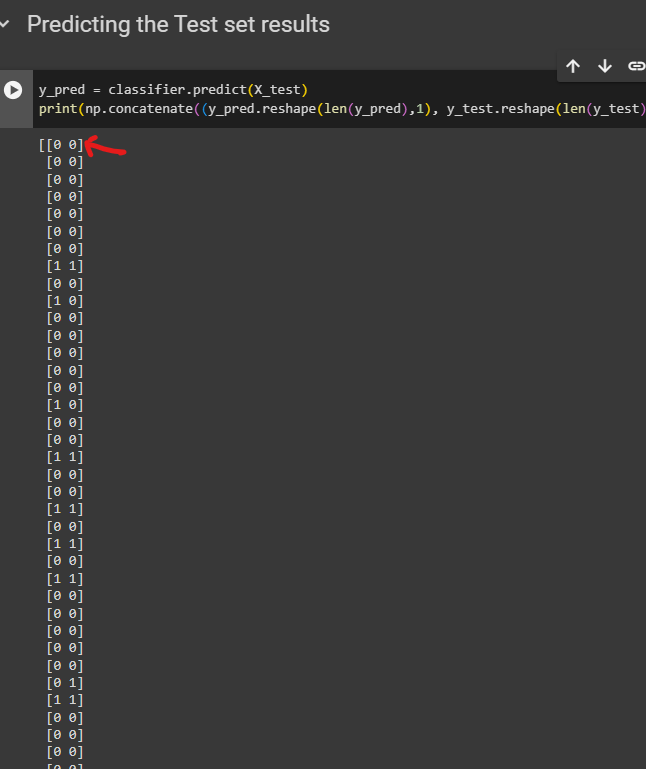
here left 0 means the prediction was that a person did not buy SUV and right 0 means that person actually did not by the SUV.
Making the Confusion Matrix
Confusion matrix shows how much correct we were and how much we were wrong in a matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
Checking it's accuracy
accuracy_score(y_test, y_pred)
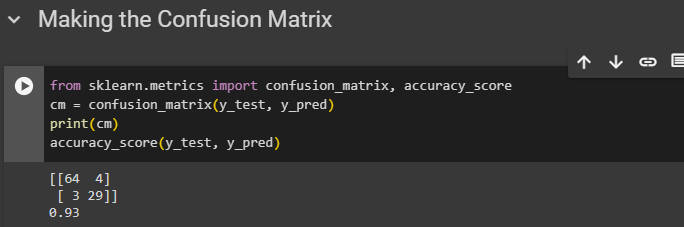
We have 93% of accuracy which is huge!!
Visualizing the Training set results
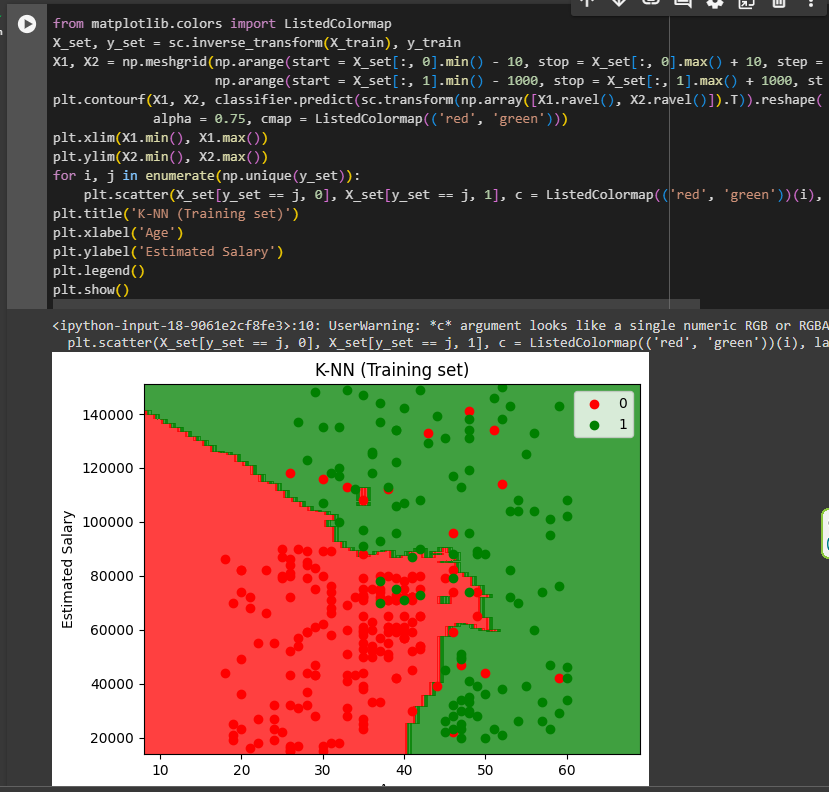
Visualizing the Test set results
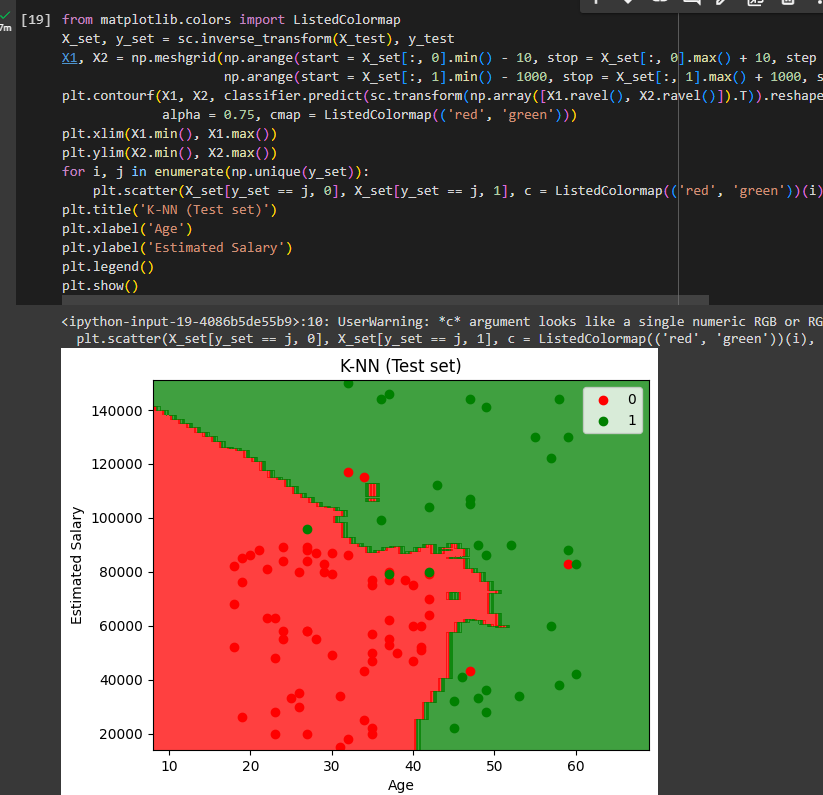
Here is the total code
Here is the dataset